小白求推荐可以本地部署DEEPSEEK和SD的台式电脑配置
[复制链接] 分享:







自己用AMD 7900xtx(24G显存)+32G内存试着本地部署了几个蒸馏后的小模型,32B能跑,14、8、7B的速度飞起,但也只能娱乐一下,跟在线版本的完全体R1不能比。而且用起来会有各种各样的小Bug,对话长度深度也会受性能限制。如果只是用现有硬件玩玩还可以,要是认真用的话要么搭个多卡集群上完整模型(应该超过了小白考虑的范畴),要么看看国内这些厂商有没有自己部署后开放的api吧。
liujiaabcde (此魂何甘归故土) 在 ta 的帖子中提到:
内存32G,硬盘2T,
其他的求推荐个配置
自己组装是不是比买品牌的划算一些?
AMD的显卡不支持CUDA也能流畅运行吗?现在OLLAMA兼容性做的这么好了吗
brainstorm (火星人) 在 ta 的帖子中提到:
自己用AMD 7900xtx(24G显存)+32G内存试着本地部署了几个蒸馏后的小模型,32B能跑,14、8、7B的速度飞起,但也只能娱乐一下,跟在线版本的完全体R1不能比。而且用起来会有各种各样的小Bug,对话长度深度也会受性能限制。如果只是用现有硬件玩玩还可以,要是认真用的话要么搭个多卡集群上完整模型(应该超过了小白考虑的范畴),要么看看国内这些厂商有没有自己部署后开放的api吧。
amd社区和LM studio宣传稿都有相关教程。
今天我详细看了下相关信息,分享
社区的实现教程:
AMD AI PC宣传稿:
AMD
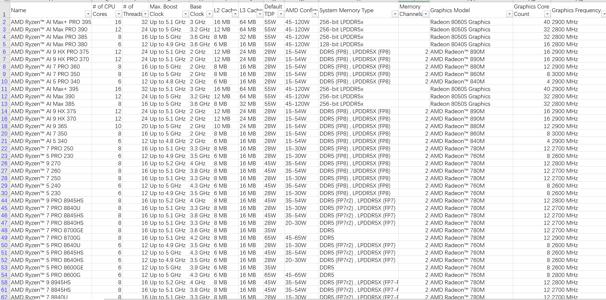
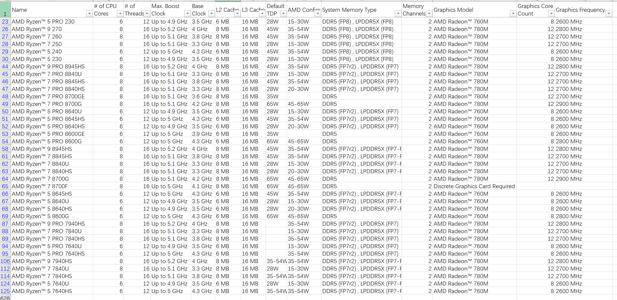
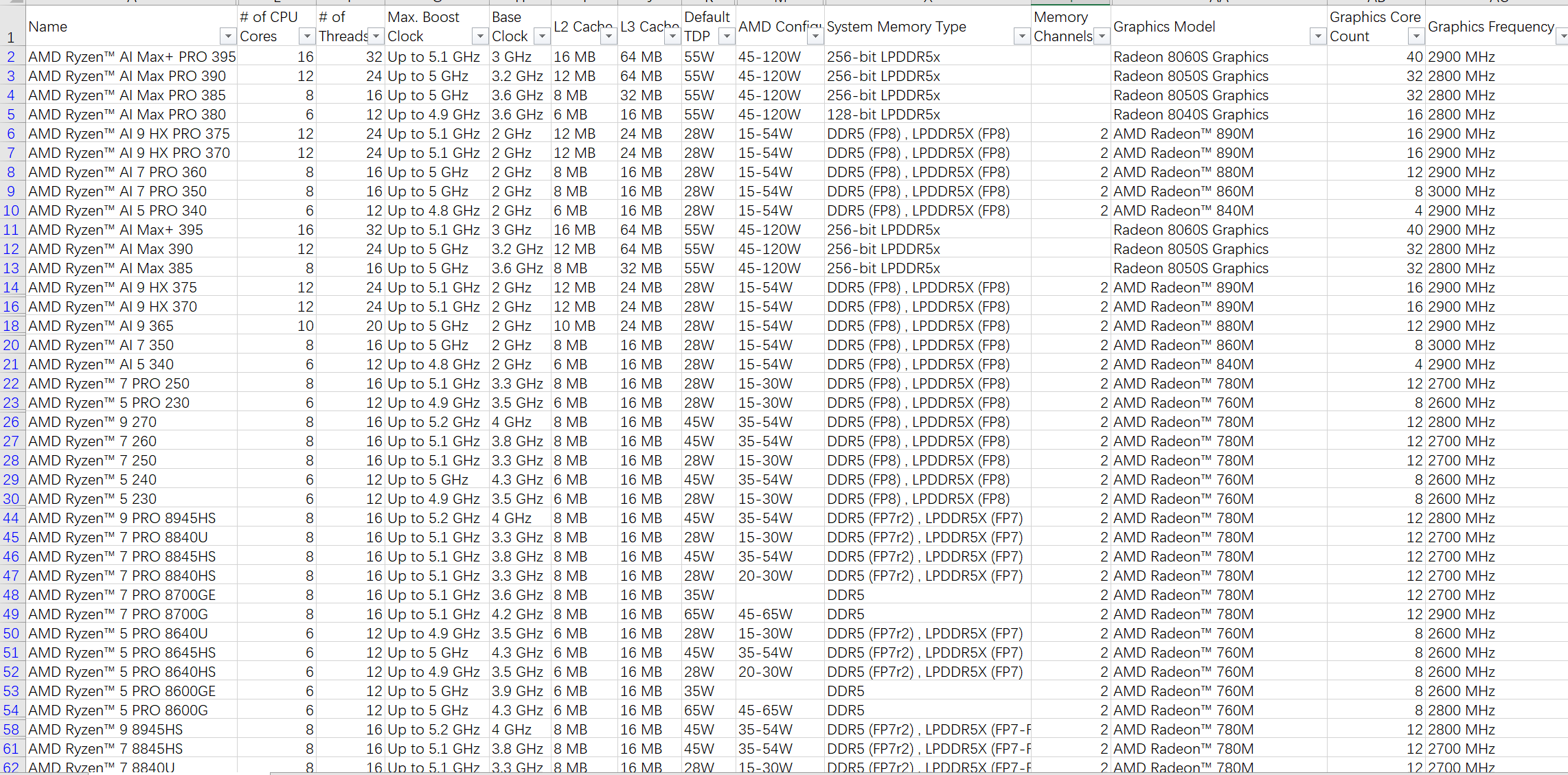
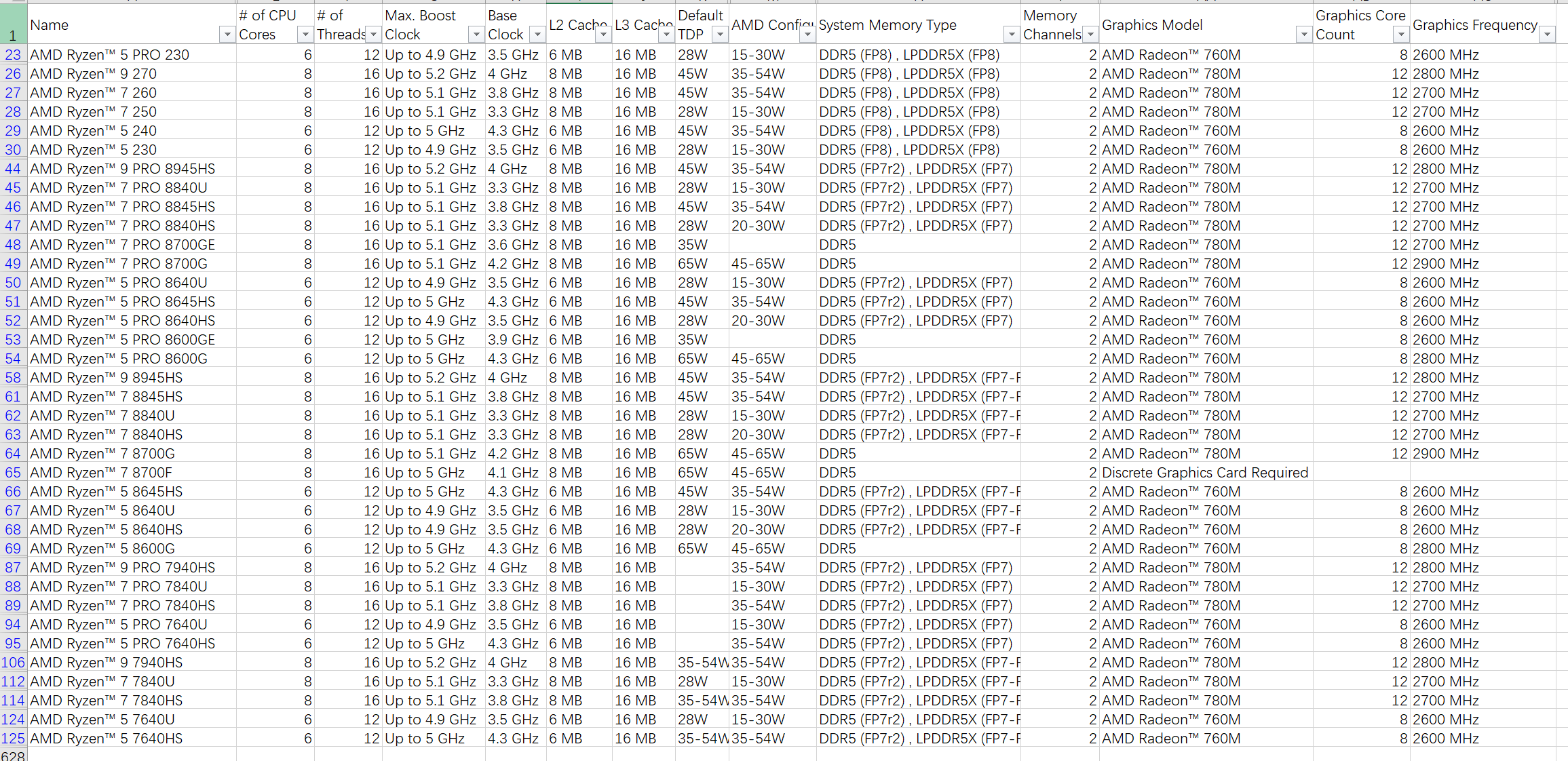
附件csv是AMD全部processor,下载子自AMD官网
两张图片是支持AMD AI的processor
liujiaabcde (此魂何甘归故土) 在 ta 的帖子中提到:
内存32G,硬盘2T,
其他的求推荐个配置
自己组装是不是比买品牌的划算一些?

- amd_processor.png(321.5KB)
- amd_processor-2.png(318.0KB)
- AMD Processor Specifications.csv(265.1KB)

不支持的显卡你可以看到显存占用接近0,会直接走内存
LYMing (老玉米) 在 ta 的帖子中提到:
Intel核显也可以跑
但是慢,不推荐
- IMG_7954.jpeg(2.5MB)
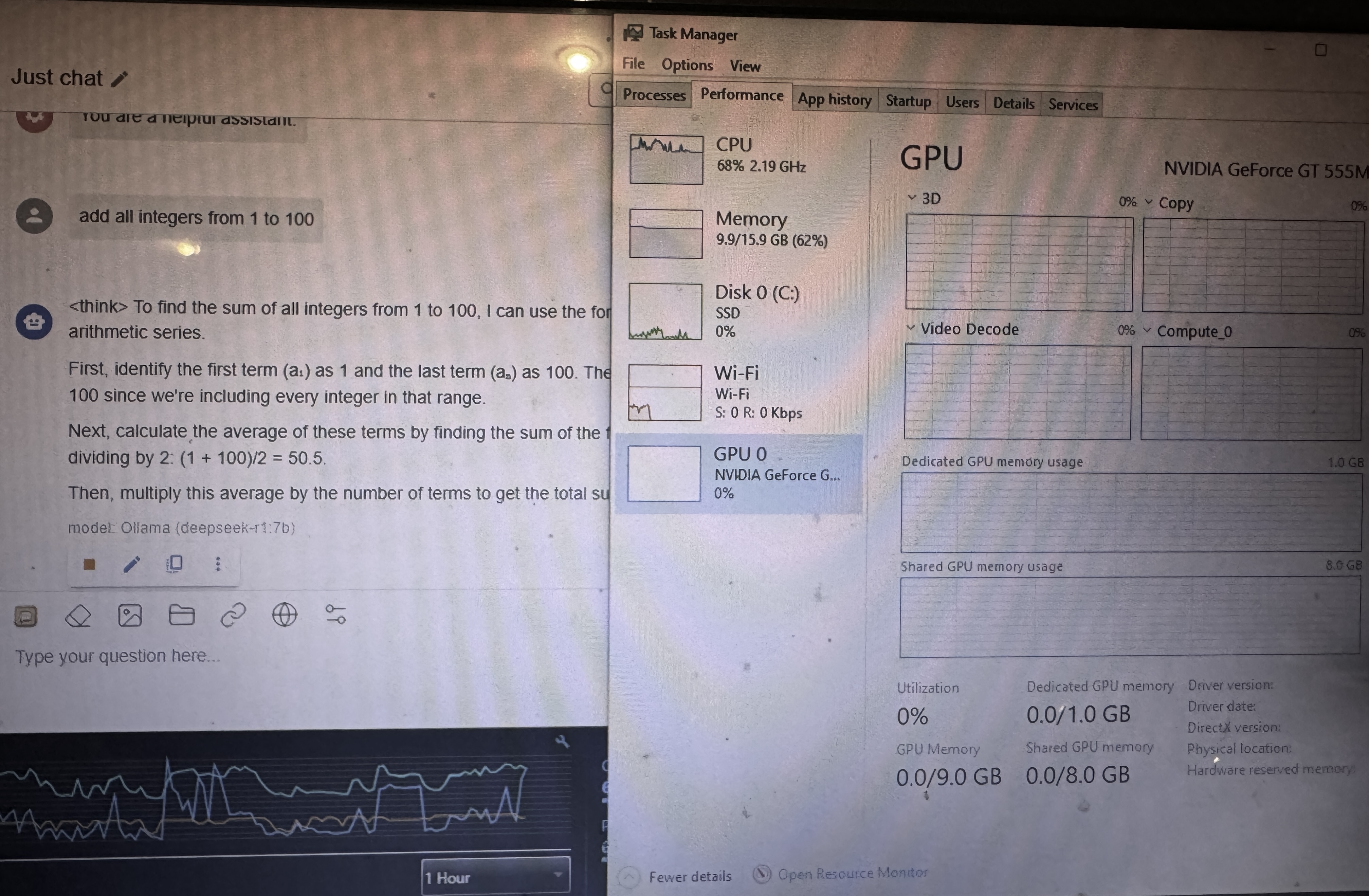
爆内存没办法,即使开虚拟内存那也慢到无法接受了,不过恰好超过内存一半容量占用的时候因为shared GPU memory限制,反而直接全部转移到内存里,是之前没想到的场景
不知道新款64G轻薄核显本用户用70b的时候是啥情况,但11代处理器70b和7b没区别,新款估计7b会快很多
LYMing (老玉米) 在 ta 的帖子中提到:
十几年前的GPU肯定不行,我看视频 大家都是用的Intel Ultra核显
爆内存没辙,狠狠的加内存吧
至少插满32G单条,48G单条也可以考虑
……
签名档
Apply:12
Offer:0
AD:1
Reject:11